西洋棋 AI 技術演進:從深藍到 AlphaZero 的革命Chess AI Technology Evolution: The Revolution from Deep Blue to AlphaZero
📅 發布日期📅 Published: 2025-01-27⏱️ 閱讀時間⏱️ Reading Time: 10 分鐘10 min🏷️ 分類: AI 技術Category: AI Technology
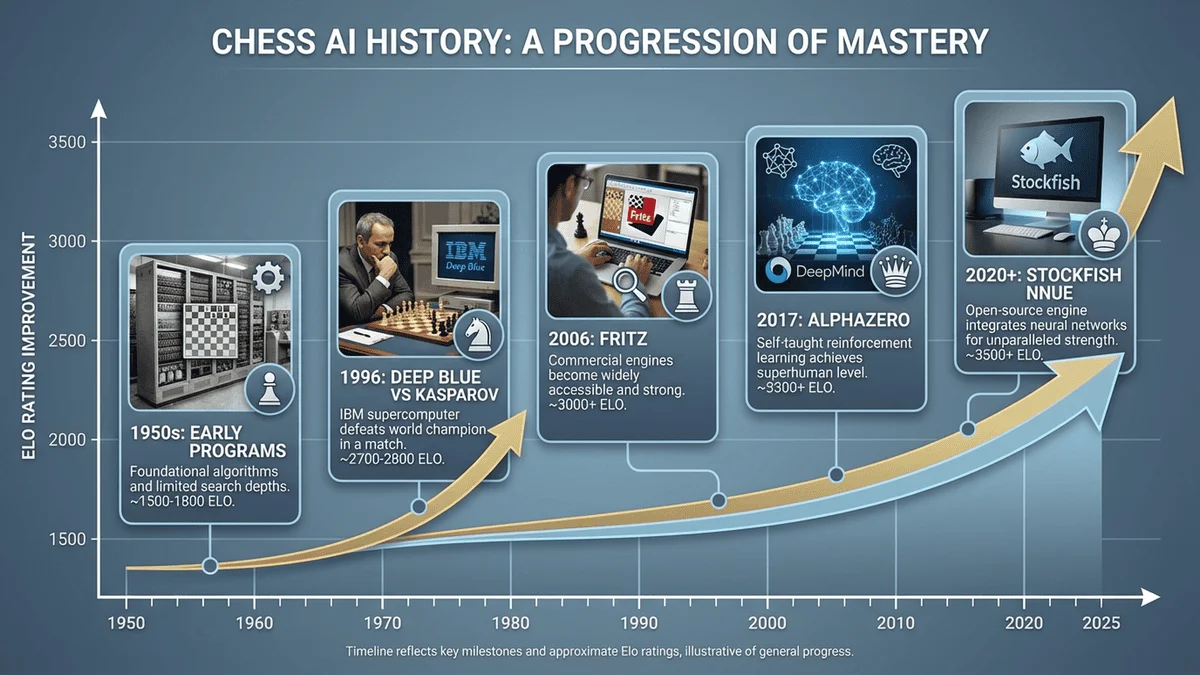
西洋棋AI發展歷史時間線
引言:人機對弈的里程碑Introduction: Milestones in Human-Machine Chess
1997 年 5 月 11 日,IBM 的超級電腦「深藍」(Deep Blue)擊敗了當時的世界西洋棋冠軍加里·卡斯帕羅夫(Garry Kasparov),這一事件標誌著人工智慧發展史上的重要轉捩點。從那時起,西洋棋 AI 技術經歷了超過 25 年的飛速發展,從依賴暴力搜尋的傳統引擎,演化到基於深度學習的自我進化系統。On May 11, 1997, IBM's supercomputer "Deep Blue" defeated the world chess champion Garry Kasparov, marking a crucial turning point in AI history. Since then, chess AI technology has undergone over 25 years of rapid development, evolving from traditional engines relying on brute-force search to self-evolving systems based on deep learning.
本文將深入探討西洋棋 AI 的技術演進歷程,分析關鍵技術突破,並展望未來發展趨勢。無論你是 AI 研究者、西洋棋愛好者,還是對人機對弈感興趣的讀者,都能從中獲得寶貴的見解。This article will explore the technological evolution of chess AI, analyze key technical breakthroughs, and look ahead to future trends. Whether you're an AI researcher, chess enthusiast, or simply interested in human-machine competition, you'll gain valuable insights.
"西洋棋是智力的試金石。" — 歌德
而今天,AI 已經成為這塊試金石上最耀眼的金子。"Chess is the touchstone of intellect." — Goethe
And today, AI has become the brightest gold on this touchstone.
深藍對決卡斯帕羅夫歷史對局
第一階段:深藍時代(1989-2006)Phase One: The Deep Blue Era (1989-2006)
深藍的誕生與勝利The Birth and Victory of Deep Blue
深藍是 IBM 開發的專用西洋棋超級電腦,其核心技術包括:Deep Blue was a purpose-built chess supercomputer developed by IBM. Its core technologies included:
🔧 深藍核心技術🔧 Deep Blue Core Technologies
並行處理Parallel Processing:480 顆專用西洋棋晶片,每秒可評估 2 億個棋步: 480 dedicated chess chips, evaluating 200 million positions per second
深度搜尋Deep Search:使用 Alpha-Beta 剪枝算法,平均搜尋深度 12 層,關鍵局面可達 40 層: Alpha-Beta pruning algorithm, average search depth of 12 plies, up to 40 in critical positions
開局庫Opening Book:包含超過 70 萬個大師級對局的開局數據庫: Database containing over 700,000 master-level games
殘局表Endgame Tables:6 子及以下殘局的完全解答庫: Complete solutions for 6-piece and fewer endgames
評估函數Evaluation Function:約 8,000 個手工調整的參數,評估位置優劣: About 8,000 hand-tuned parameters for position evaluation
1989
深思(Deep Thought)誕生Deep Thought is Born
深藍的前身,首次挑戰卡斯帕羅夫但落敗Predecessor to Deep Blue, first challenged Kasparov but lost
1996
深藍首次對決Deep Blue's First Match
深藍與卡斯帕羅夫首次對弈,以 2-4 落敗,但贏下首局Deep Blue's first match against Kasparov, lost 2-4 but won game one
1997
人類的失敗Humanity's Defeat
升級後的深藍以 3.5-2.5 擊敗卡斯帕羅夫,震驚世界Upgraded Deep Blue defeated Kasparov 3.5-2.5, shocking the world
2006
深藍退役Deep Blue Retired
IBM 宣布深藍項目結束,標誌著第一代西洋棋 AI 時代的終結IBM announced end of Deep Blue project, marking the end of first-generation chess AI era
傳統引擎的核心算法Core Algorithms of Traditional Engines
深藍時代的西洋棋 AI 主要依賴以下算法:Chess AI in the Deep Blue era primarily relied on the following algorithms:
function alphaBeta(position, depth, alpha, beta, isMaximizing) {
// 基礎情況:達到搜尋深度或遊戲結束
if (depth == 0 || isGameOver(position)) {
return evaluatePosition(position);
}
if (isMaximizing) {
let maxEval = -Infinity;
for (let move of getAllMoves(position)) {
let eval = alphaBeta(makeMove(position, move),
depth - 1, alpha, beta, false);
maxEval = Math.max(maxEval, eval);
alpha = Math.max(alpha, eval);
// Beta 剪枝:無需繼續搜尋
if (beta <= alpha) break;
}
return maxEval;
} else {
let minEval = Infinity;
for (let move of getAllMoves(position)) {
let eval = alphaBeta(makeMove(position, move),
depth - 1, alpha, beta, true);
minEval = Math.min(minEval, eval);
beta = Math.min(beta, eval);
// Alpha 剪枝
if (beta <= alpha) break;
}
return minEval;
}
}
// 評估函數範例(簡化版)
function evaluatePosition(position) {
let score = 0;
// 1. 材料價值
score += countMaterial(position);
// 2. 位置控制
score += evaluatePieceSquareTables(position);
// 3. 國王安全
score += evaluateKingSafety(position);
// 4. 兵形結構
score += evaluatePawnStructure(position);
// 5. 機動性
score += evaluateMobility(position);
return score;
}
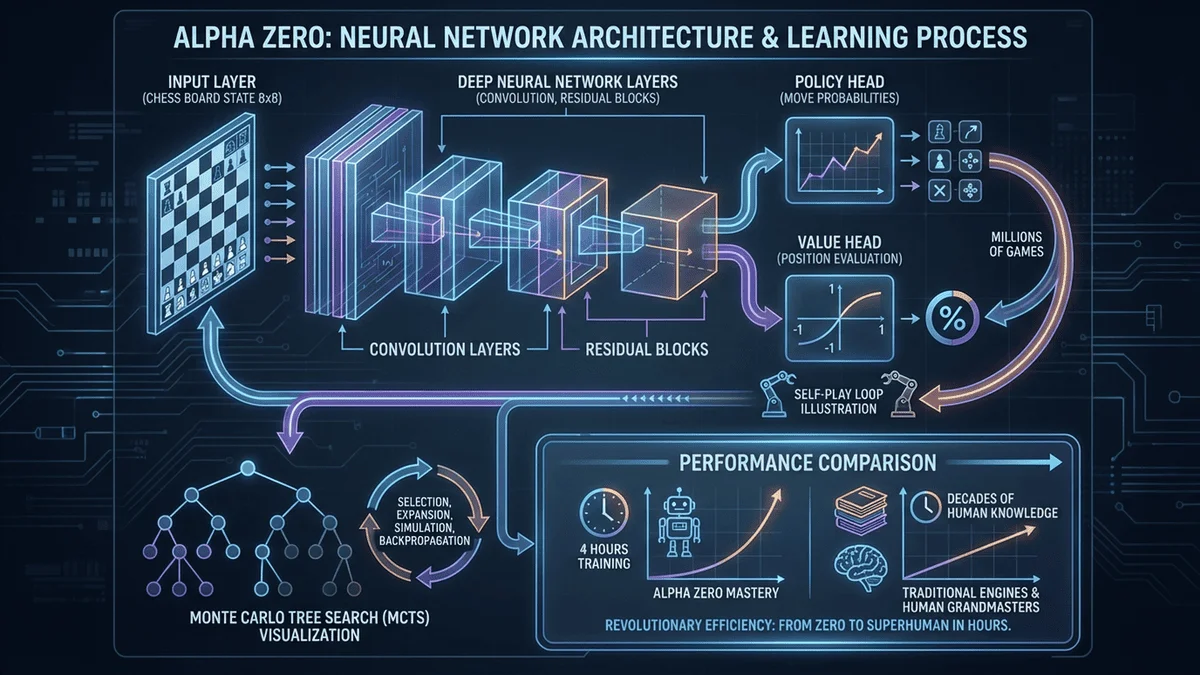
AlphaZero神經網路架構圖
第二階段:現代引擎時代(2007-2016)Phase Two: The Modern Engine Era (2007-2016)
Stockfish:開源的王者Stockfish: The Open-Source King
Stockfish 是當今最強大的開源西洋棋引擎之一,於 2008 年首次發布。其技術創新包括:Stockfish is one of the most powerful open-source chess engines today, first released in 2008. Its technical innovations include:
多核並行Multi-core Parallel:充分利用現代多核 CPU,支援最多 512 個執行緒: Fully utilizes modern multi-core CPUs, supports up to 512 threads
智能搜尋Smart Search:Late Move Reduction (LMR)、Null Move Pruning 等先進剪枝技術: Advanced pruning techniques like Late Move Reduction (LMR), Null Move Pruning
動態評估Dynamic Evaluation:根據局面類型動態調整評估權重: Dynamically adjusts evaluation weights based on position type
從位置數據直接學習評估Learn evaluation directly from position data
比傳統評估函數快 10 倍,且更準確10x faster than traditional functions, more accurate
第三階段:深度學習革命(2017-現在)Phase Three: The Deep Learning Revolution (2017-Present)
AlphaZero:範式轉移AlphaZero: A Paradigm Shift
2017 年 12 月,DeepMind 發表的 AlphaZero 震驚了整個 AI 和西洋棋界。這個系統僅通過自我對弈,在 4 小時內就達到了超越 Stockfish 的水平。In December 2017, DeepMind's AlphaZero shocked the entire AI and chess world. Through self-play alone, this system reached a level surpassing Stockfish in just 4 hours.
"AlphaZero 的下法有時違反傳統棋理,但最終卻被證明是正確的。它重新定義了我們對西洋棋的理解。"
— 弗拉基米爾·克拉姆尼克(前世界冠軍)"AlphaZero's moves sometimes violate conventional chess wisdom, but ultimately prove to be correct. It redefines our understanding of chess."
— Vladimir Kramnik (Former World Champion)
受 AlphaZero 啟發,社群開發了開源版本 Leela Chess Zero (Lc0):Inspired by AlphaZero, the community developed the open-source Leela Chess Zero (Lc0):
開放架構Open Architecture:任何人都可以貢獻訓練數據和改進算法: Anyone can contribute training data and improve algorithms
分散式訓練Distributed Training:利用全球志願者的計算資源: Utilizes computing resources from global volunteers
持續進化Continuous Evolution:每天進行數百萬局自我對弈: Millions of self-play games daily
接近頂尖Near Top Level:目前 Elo 約 3500+,與 Stockfish 競爭: Current Elo ~3500+, competing with Stockfish
技術對比與未來展望Technical Comparison and Future Outlook
三代技術的核心差異Core Differences Across Three Generations
維度Dimension
深藍時代Deep Blue Era
現代引擎Modern Engines
深度學習Deep Learning
知識來源Knowledge Source
人類專家Human Experts
數據+專家Data + Experts
純自我學習Pure Self-Learning
評估方式Evaluation Method
手工函數Hand-Crafted
優化函數+NNUEOptimized + NNUE
深度神經網路Deep Neural Network
搜尋策略Search Strategy
暴力+剪枝Brute Force + Pruning
智能剪枝Smart Pruning
MCTS+神經網路MCTS + Neural Net
計算需求Compute Needs
專用硬體Dedicated Hardware
通用 CPUGeneral CPU
GPU/TPU
訓練時間Training Time
數月調參Months of Tuning
數週自動化Weeks Automated
數小時到數天Hours to Days
未來發展趨勢Future Development Trends
🔮 西洋棋 AI 的未來方向🔮 Future Directions of Chess AI
混合架構Hybrid Architecture
結合傳統搜尋和神經網路的優勢Combining traditional search with neural network strengths
Stockfish NNUE 已經證明了這條路的可行性Stockfish NNUE has proven this path viable
高效訓練Efficient Training
降低 AlphaZero 級別 AI 的訓練成本Reducing training costs for AlphaZero-level AI
讓個人開發者也能訓練強大引擎Enabling individual developers to train powerful engines
可解釋性Explainability
理解神經網路「為什麼」選擇某個移動Understanding "why" neural networks choose certain moves
將 AI 的棋理轉化為人類可理解的概念Translating AI chess logic into human-understandable concepts
教學應用Educational Applications
開發更適合人類學習的 AI 教練Developing AI coaches better suited for human learning
針對不同水平玩家提供個性化訓練Personalized training for players of different levels
多遊戲通用Multi-Game General
AlphaZero 已證明可以掌握西洋棋、圍棋、將棋AlphaZero has proven mastery of chess, Go, and Shogi
未來可能出現通用棋類 AIUniversal board game AI may emerge in the future
結語:AI 重新定義西洋棋Conclusion: AI Redefining Chess
從深藍擊敗卡斯帕羅夫到 AlphaZero 的自我學習革命,西洋棋 AI 的發展歷程濃縮了人工智慧領域 70 年的探索。今天,最強的西洋棋引擎已經遠遠超越人類棋手,但這並非終點,而是新起點。From Deep Blue defeating Kasparov to AlphaZero's self-learning revolution, the evolution of chess AI encapsulates 70 years of exploration in the field of artificial intelligence. Today, the strongest chess engines have far surpassed human players, but this is not the end—it's a new beginning.
AI 不僅改變了我們對西洋棋的理解,更啟發了新的棋理和策略。許多被認為「不可能」的下法,在 AI 的驗證下被證明是正確的。這種人機協作的模式,正在重新塑造整個西洋棋世界。AI has not only changed our understanding of chess but also inspired new theories and strategies. Many moves once considered "impossible" have been proven correct through AI validation. This human-machine collaboration model is reshaping the entire chess world.
💡 關鍵啟示💡 Key Insights
技術演進從「模仿人類」到「超越人類」再到「啟發人類」Technology evolved from "imitating humans" to "surpassing humans" to "inspiring humans"
深度學習證明了「從零開始」學習的可能性Deep learning proved the possibility of learning "from scratch"
計算效率的提升遠比計算量的增加更重要Improving computational efficiency is far more important than increasing raw computing power
開源社群的力量可以媲美大公司的研發The power of open-source communities can rival corporate R&D
AI 的價值在於拓展人類認知邊界,而非取代人類AI's value lies in expanding human cognitive boundaries, not replacing humans
無論你是想提升棋力的玩家,還是研究 AI 的開發者,Tool Master 提供的西洋棋工具都能幫助你更好地理解這個迷人的領域。立即試用,體驗 AI 技術的魅力!Whether you're a player looking to improve your skills or a developer researching AI, Tool Master's chess tools can help you better understand this fascinating field. Try it now and experience the magic of AI technology!