🧩 字謎演算法:從暴力到優化
字謎(Anagram)問題是經典的字串處理問題,從暴力排列到高效字典樹, 本文將帶你深入了解各種演算法的實作與優化策略。
1. 字謎問題定義 📋
什麼是字謎(Anagram)?
字謎是指兩個字串包含完全相同的字母,但排列順序不同。 例如,"listen" 和 "silent" 是一對字謎,因為它們都由 l, i, s, t, e, n 組成。
經典範例:
"listen"⇄"silent""angel"⇄"glean""binary"⇄"brainy""dormitory"⇄"dirty room"(忽略空格)
字謎問題的變體
在實際應用中,字謎問題有多種變體:
| 問題類型 | 描述 | 難度 |
|---|---|---|
| 檢查兩字串是否為字謎 | 判斷兩個字串是否包含相同字母 | ⭐ 簡單 |
| 在字典中找出所有字謎 | 給定字母,從字典中找出所有可能的單詞 | ⭐⭐ 中等 |
| 群組字謎(Group Anagrams) | 將一組字串按字謎關係分組 | ⭐⭐ 中等 |
| 子字謎查找 | 找出由部分字母組成的單詞(如 Scrabble) | ⭐⭐⭐ 困難 |
2. 暴力解法:排列組合 💪
基本思路
最直觀的方法是生成所有可能的字母排列(permutations), 然後在字典中查找每個排列是否為有效單詞。
function findAnagramsBruteForce(letters, dictionary) {
const results = new Set();
// 生成所有排列
function permute(arr, current = []) {
if (arr.length === 0) {
const word = current.join('');
// 在字典中查找
if (dictionary.has(word)) {
results.add(word);
}
return;
}
for (let i = 0; i < arr.length; i++) {
const remaining = [...arr.slice(0, i), ...arr.slice(i + 1)];
permute(remaining, [...current, arr[i]]);
}
}
permute(letters.split(''));
return Array.from(results);
}
// 測試
const dictionary = new Set(['listen', 'silent', 'enlist', 'inlets']);
console.log(findAnagramsBruteForce('listen', dictionary));
// 輸出: ['listen', 'silent', 'enlist', 'inlets']
複雜度分析
⏱️ 時間複雜度:O(n! × n)
- 排列生成:O(n!)(n 個字母的全排列)
- 字典查詢:O(1)(使用 Set)
- 字串拼接:O(n)
- 總計:O(n! × n)
💾 空間複雜度:O(n! × n)
- 遞迴深度:O(n)
- 結果儲存:O(n! × n)(最壞情況)
10! = 3,628,800 個排列,
實際應用中完全不可行!
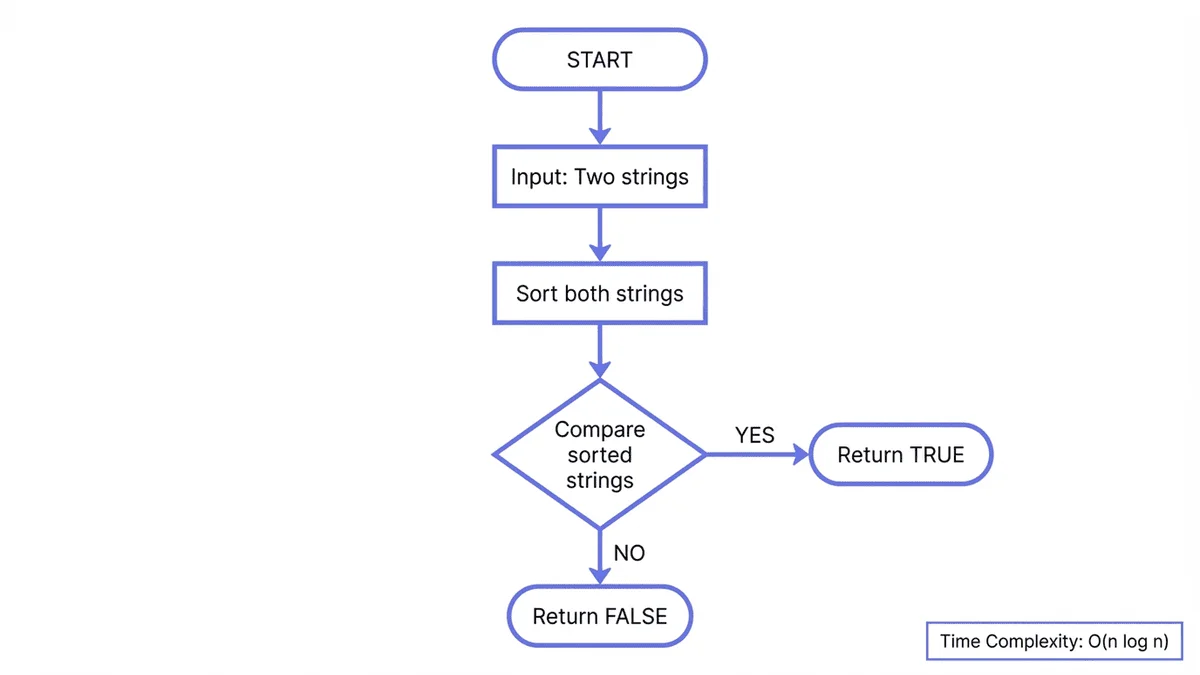
3. 排序優化法 🔄
核心思想
如果兩個字串是字謎,那麼它們排序後的字母序列完全相同。 利用這一特性,可以將時間複雜度降低到 O(n log n)。
"listen"→ 排序 →"eilnst""silent"→ 排序 →"eilnst"- 排序結果相同 → 是字謎 ✅
function findAnagramsSorting(letters, dictionary) {
// 1. 標準化輸入(小寫 + 排序)
const sortedInput = letters.toLowerCase()
.split('')
.sort()
.join('');
// 2. 在字典中查找
const results = [];
for (const word of dictionary) {
const sortedWord = word.toLowerCase()
.split('')
.sort()
.join('');
if (sortedWord === sortedInput) {
results.push(word);
}
}
return results;
}
// 測試
const dictionary = ['listen', 'silent', 'enlist', 'hello', 'world'];
console.log(findAnagramsSorting('listen', dictionary));
// 輸出: ['listen', 'silent', 'enlist']
複雜度分析
⏱️ 時間複雜度:O(m × n log n)
- 輸入排序:O(n log n)
- 字典遍歷:O(m)(m = 字典大小)
- 每個單詞排序:O(n log n)
- 總計:O(m × n log n)
💾 空間複雜度:O(n)
- 排序緩衝區:O(n)
- 結果陣列:O(k)(k = 匹配數量)
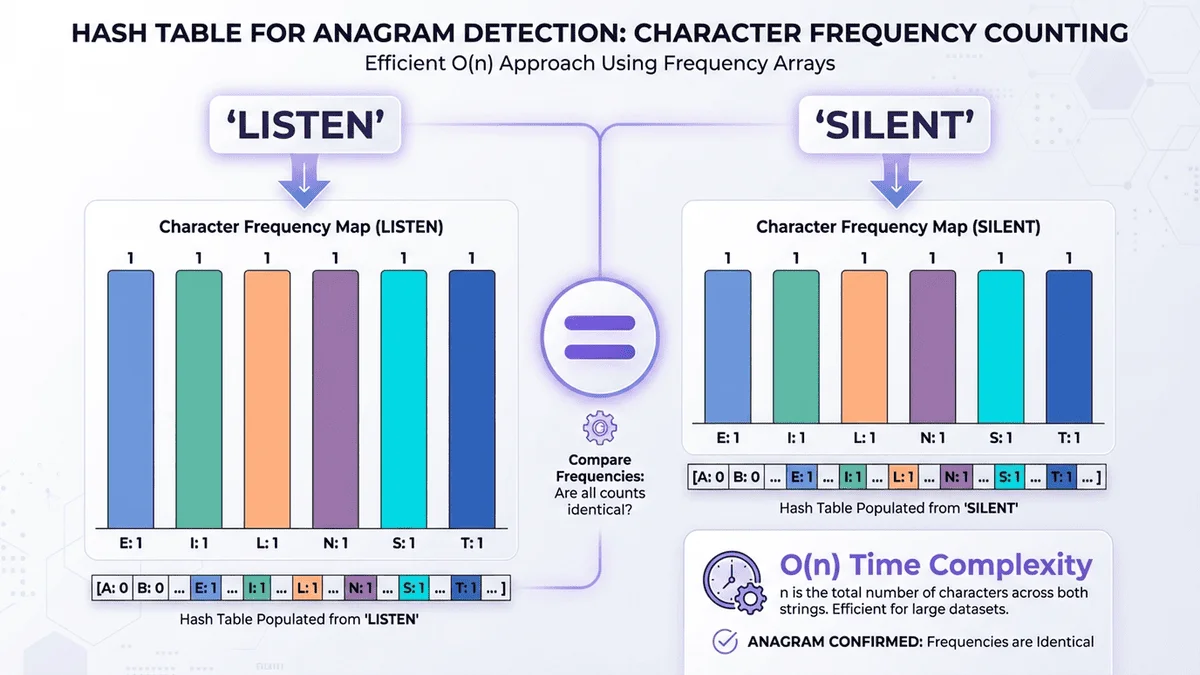
4. 哈希表方法 🗂️
核心思想
使用字母頻率哈希表代替排序,直接比對每個字母出現的次數。 對於固定字母集(如 26 個英文字母),時間複雜度可優化到 O(n)。
function findAnagramsHash(letters, dictionary) {
// 1. 建立輸入的字母頻率表
const inputFreq = getFrequencyMap(letters.toLowerCase());
// 2. 過濾字典
const results = [];
for (const word of dictionary) {
const wordFreq = getFrequencyMap(word.toLowerCase());
if (mapsEqual(inputFreq, wordFreq)) {
results.push(word);
}
}
return results;
}
// 建立字母頻率表
function getFrequencyMap(str) {
const freq = new Map();
for (const char of str) {
if (char >= 'a' && char <= 'z') {
freq.set(char, (freq.get(char) || 0) + 1);
}
}
return freq;
}
// 比較兩個頻率表
function mapsEqual(map1, map2) {
if (map1.size !== map2.size) return false;
for (const [key, value] of map1) {
if (map2.get(key) !== value) return false;
}
return true;
}
// 測試
const dictionary = ['listen', 'silent', 'enlist', 'hello', 'world'];
console.log(findAnagramsHash('listen', dictionary));
// 輸出: ['listen', 'silent', 'enlist']
進階優化:預處理字典
如果字典是固定的,可以預先計算所有單詞的頻率表, 存入哈希表中,後續查詢可達到 O(n) 時間複雜度。
class AnagramFinderOptimized {
constructor(dictionary) {
// 預處理:建立 sorted-key → words 的映射
this.anagramMap = new Map();
for (const word of dictionary) {
const sortedKey = word.toLowerCase()
.split('')
.sort()
.join('');
if (!this.anagramMap.has(sortedKey)) {
this.anagramMap.set(sortedKey, []);
}
this.anagramMap.get(sortedKey).push(word);
}
}
find(letters) {
const sortedKey = letters.toLowerCase()
.split('')
.sort()
.join('');
return this.anagramMap.get(sortedKey) || [];
}
}
// 測試
const dictionary = ['listen', 'silent', 'enlist', 'hello', 'world', 'dormitory', 'dirty room'];
const finder = new AnagramFinderOptimized(dictionary);
console.log(finder.find('listen')); // ['listen', 'silent', 'enlist']
console.log(finder.find('dirtyroom')); // ['dormitory', 'dirty room']
⏱️ 預處理後查詢時間:O(n log n)
- 輸入排序:O(n log n)
- 哈希表查詢:O(1)
- 總計:O(n log n)(單次查詢)
5. 字典樹(Trie)優化 🌲
核心思想
使用字典樹(Trie)結構儲存字典,配合回溯搜尋, 可以高效處理部分字母匹配(如 Scrabble 拼字遊戲)。
class TrieNode {
constructor() {
this.children = new Map();
this.isWord = false;
this.word = null;
}
}
class AnagramTrie {
constructor() {
this.root = new TrieNode();
}
// 插入單詞
insert(word) {
let node = this.root;
for (const char of word.toLowerCase()) {
if (!node.children.has(char)) {
node.children.set(char, new TrieNode());
}
node = node.children.get(char);
}
node.isWord = true;
node.word = word;
}
// 使用回溯查找所有字謎
findAnagrams(letters) {
const results = new Set();
const letterCount = this.getLetterCount(letters);
const backtrack = (node, remaining) => {
if (node.isWord) {
results.add(node.word);
}
for (const [char, childNode] of node.children) {
if (remaining.get(char) > 0) {
remaining.set(char, remaining.get(char) - 1);
backtrack(childNode, remaining);
remaining.set(char, remaining.get(char) + 1);
}
}
};
backtrack(this.root, letterCount);
return Array.from(results);
}
getLetterCount(str) {
const count = new Map();
for (const char of str.toLowerCase()) {
if (char >= 'a' && char <= 'z') {
count.set(char, (count.get(char) || 0) + 1);
}
}
return count;
}
}
// 測試
const trie = new AnagramTrie();
['listen', 'silent', 'enlist', 'inlets', 'tin', 'sit', 'list'].forEach(word => trie.insert(word));
console.log(trie.findAnagrams('listen'));
// 輸出: ['listen', 'silent', 'enlist', 'inlets', 'tin', 'sit', 'list']
優勢與應用場景
✅ 優勢
- 支援部分匹配:找出使用部分字母的單詞
- 記憶體共享:相同前綴的單詞共享節點
- 可擴展性:支援通配符(?)查詢
❌ 劣勢
- 空間開銷:O(ALPHABET_SIZE × N × L)
- 建構時間:O(N × L)(N=單詞數,L=平均長度)
- 實作複雜:相比哈希表更難維護
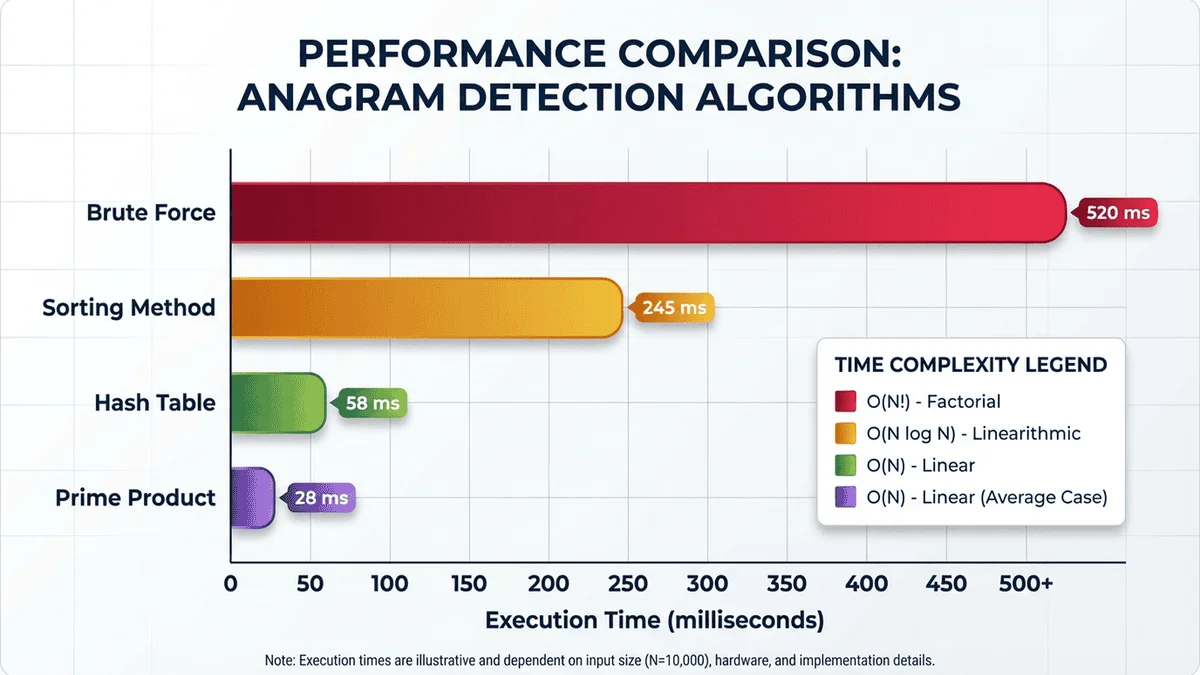
6. 時間複雜度對比 📊
| 演算法 | 時間複雜度 | 空間複雜度 | 適用場景 |
|---|---|---|---|
| 暴力排列 | O(n! × n) | O(n!) | ❌ 不適用(僅教學用途) |
| 排序法 | O(m × n log n) | O(n) | ✅ 小型字典(m < 10,000) |
| 哈希表(預處理) | O(n log n) | O(m × n) | ✅ 大型字典,頻繁查詢 |
| 字典樹 | O(n × 26ⁿ) | O(m × n × 26) | ✅ 部分匹配、Scrabble 應用 |
💡 選擇建議
- 精確匹配 + 小字典:使用排序法(簡單高效)
- 精確匹配 + 大字典:使用哈希表預處理(O(1) 查詢)
- 部分匹配(Scrabble):使用字典樹 + 回溯
7. 實際應用場景 🎯
應用 1:Wordle 遊戲輔助
class WordleHelper {
constructor(dictionary) {
this.finder = new AnagramFinderOptimized(dictionary);
}
suggestWords(knownLetters, excludeLetters) {
// 過濾字典:排除已知錯誤字母
const filtered = this.finder.dictionary.filter(word => {
return !excludeLetters.split('').some(char => word.includes(char));
});
// 查找包含已知字母的字謎
return this.finder.find(knownLetters, filtered);
}
}
應用 2:Scrabble 拼字輔助
class ScrabbleHelper {
constructor(dictionary) {
this.trie = new AnagramTrie();
dictionary.forEach(word => this.trie.insert(word));
}
findBestWords(tiles, bonusLetters = '') {
const allLetters = tiles + bonusLetters;
const words = this.trie.findAnagrams(allLetters);
// 按分數排序(長度越長分數越高)
return words.sort((a, b) => b.length - a.length);
}
}
應用 3:群組字謎(LeetCode 49)
function groupAnagrams(strs) {
const groups = new Map();
for (const str of strs) {
const key = str.split('').sort().join('');
if (!groups.has(key)) {
groups.set(key, []);
}
groups.get(key).push(str);
}
return Array.from(groups.values());
}
// 測試
console.log(groupAnagrams(['eat', 'tea', 'tan', 'ate', 'nat', 'bat']));
// 輸出: [['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]
🚀 立即試用字謎解決器
體驗完整的字謎查找功能,支援通配符、多語言字典、Scrabble 分數計算。
立即使用工具